Creating Human-like Bots For First Person Shooters
After years of playing FPS games, I developed an interest in “aim duel 1v1s” in which players aim/shoot at each other while simultaneously dodging their opponent’s attack. The winning players in such duels are those who most effectively learn to read their enemies while making themselves harder to read. The mechanics of Quake 3, with fast movement and aim/strafe acceleration that help exaggerate mistakes, makes this FPS game a particularly excellent environment to investigate this topic.
A bot trained with self-play, playing against itself. It learned to be as accurate as possible, avoiding dodging.
The Problem
What makes a player hard to hit? Purely random movement seems appealing, yet many “random” behaviors are still exploitable because they let the opponent choose favorable positioning. For example, if a player jitters randomly in place with no directional bias, their opponent can counter by circling around them, forcing difficult mouse aim positions.
Dodging can theoretically be broken into categories of deliberate movement:
- Anti-aim: Eliciting difficult aiming situations regardless of pattern or predictability. This causes a difficult aiming movement despite knowing where the target is moving. (awkward angles, jittering, high required aiming velocities)
- Anti-reaction: Any fast maneuver that forces late corrections, caused by sharp acceleration changes or mis-predictions.
- Anti-learning: Imposing complexity. Over a time span, preventing the enemy from understanding a rhythm or set of patterns. This also includes strategy, a pattern of patterns, which usually tend to some heuristic and prioritize a goal, such as trying to shoot at your opponent’s sides.
Effective dodging requires a structure. A variance in timing and direction that are difficult to infer over the short term, an adaptation and awareness of the enemy’s patterns (such as when they’re hitting/missing), while also moving towards optimal positioning and geometry. Stronger players recognize a wide set of common movements and reactions, so if aiming skill and reaction times are even between opponents, a particular strategy is only valuable while it stays ahead of the opponent’s rate of learning.
It’s difficult to showcase what is predictable or unpredictable because it lies entirely on the individual player’s skill. With time and experience, players learn common enemy reactions and fight positions, and can gain ability to perform accordingly to more and more unique situations.
Method
In order to properly study these mechanics and create human-like bots, developing a custom platform emulating parts of Quake 3 was necessary. Various technical decisions were made with future plans in mind. Based on prior attempts and failures at scripting and self-play bots imitation learning seemed like a natural next step, so the platform was designed to collect and process human gameplay.
Why Imitation Learning?
After scripted bots proved too exploitable and self-play kept collapsing (more on both later), imitation learning became the obvious path forward. We can bootstrap from human movement data to get baseline human-like behavior, then potentially use RL to improve beyond human level.
This shaped the entire system design. We need infrastructure to record human gameplay, a training pipeline to learn from it, and deployment back into the game.
Further research also confirmed the value of imitation learning in approaching human-like gameplay: AlphaStar and Learning to Move Like Professional Counter-Strike Players.
Implementation
Why Build From Scratch?
Off-the-shelf engines introduce unnecessary complexity and bloat for what I needed. The game mechanics are simple physics and a basic hitscan weapon, nothing requiring a full physics engine or rendering pipeline. Building from scratch gives maximum performance and direct control over all aspects. Since the platform is the core product, it’s clear that building it from scratch was the best option.
Although the Quake 3 engine is open source, there are some limitations with the demo system that would hinder future results.
Architecture
A shared deterministic simulation core that powers both training and gameplay:
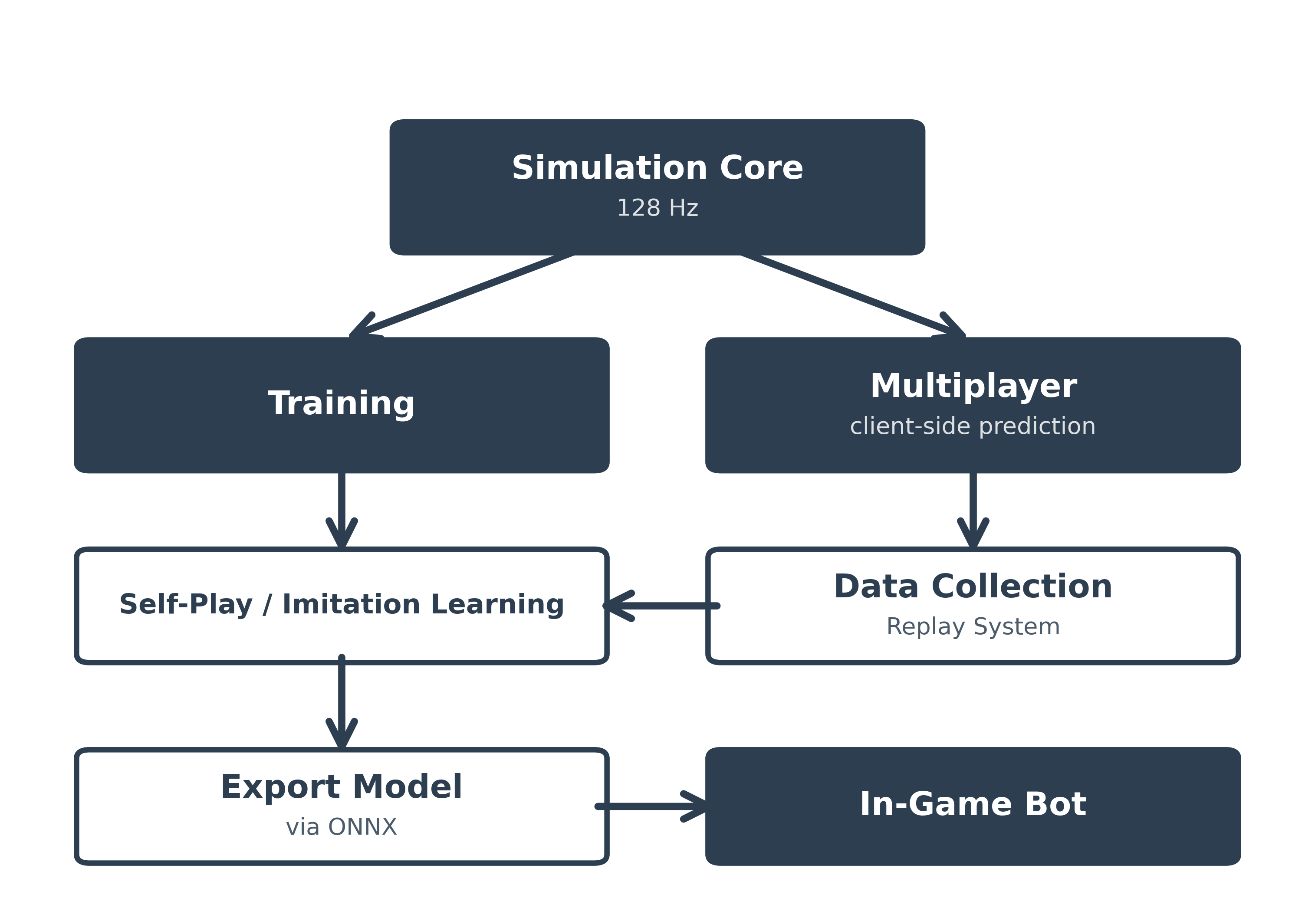
Training: To maximize throughput, I ported the simulation core to CUDA for parallel execution on a GPU. Outputs and state were verified through testing against the pure C++ simulation. This achieves about 1.4 million steps/second (action replay 1) on an RTX 3080Ti with 12GB of VRAM. For self-play, the policy trains with PPO using PyTorch, then exports to ONNX for in-game inference. Periodic replays are recorded during training for tuning and debugging.
Multiplayer: Full Quake-style netcode with client-side prediction, server reconciliation, and lag compensation. Uses the same 128Hz deterministic physics as training. Records human gameplay for imitation learning datasets.
Important Technical Aspects
- Collecting Data: Multiplayer is required for high level human-human gameplay to collect data.
- Reproducibility: A deterministic environment helps enable stability and faster learning.
- Training Speed: Simulation speed needs to be maximized, faster iterations means faster experiment turnaround, as well as more potential learning.
These requirements align towards a shared, deterministic simulation core running at a fixed timestep, giving:
- Identical simulation environment during training, multiplayer (human vs human), singleplayer (human vs bot)
- Reproducible training runs and debugging
- Ability to parallelize headless environments for speed
- Replay systems that perfectly reconstruct any moment for analysis
Replay Viewer
The replay system records all player inputs and game state, allowing perfect reconstruction of any match. This is crucial for debugging, analyzing strategies, and creating training datasets.
Early Attempts (Scripted Bots)
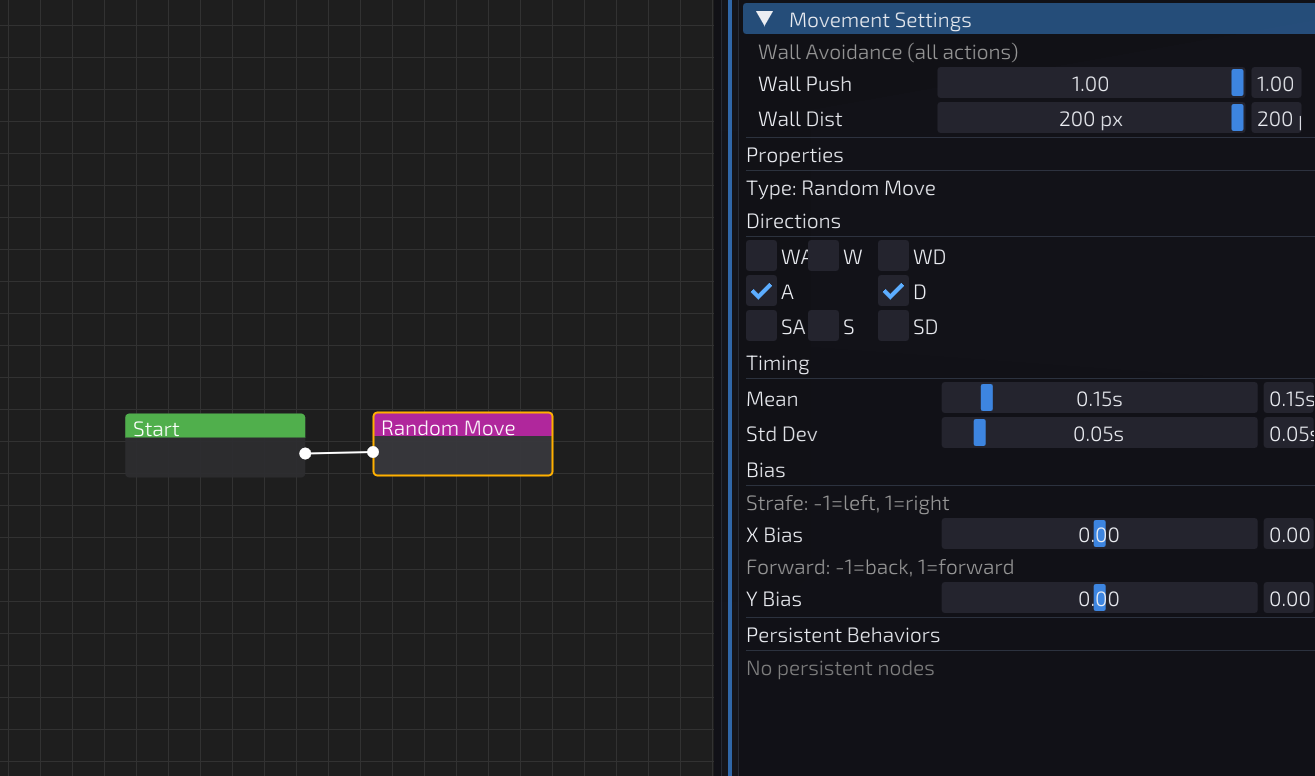
I built a node editor for stringing together observations, conditions, and actions. Distance, HP, and “am I being tracked” are connected to actions like random move, advance/retreat, and move away from crosshair. Each of these are modified through various settings.
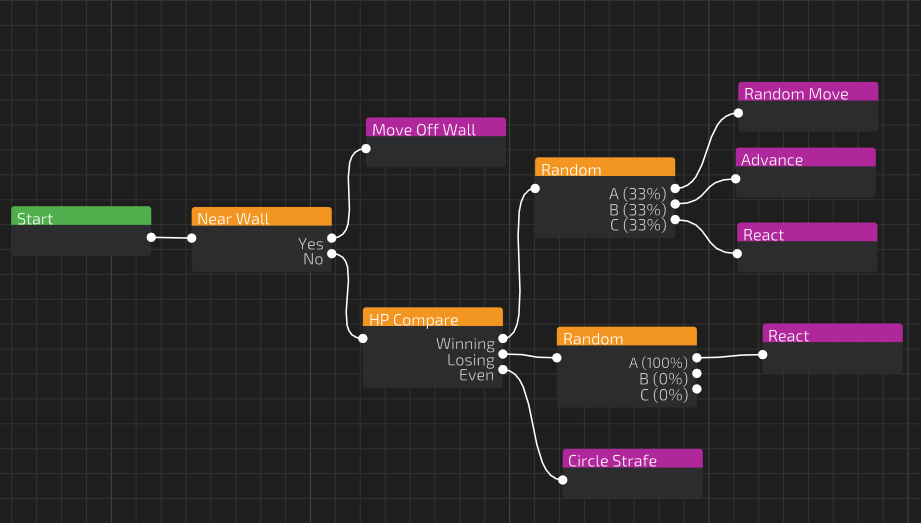
First attempt was random strafes with random timing. Hard to predict moment to moment but any basic strategy would throw it off. No awareness of the opponent at all.
Next I tried reactive heuristics:
Move away from crosshair: Works when the opponent is already missing, but if they’re on target the bot just keeps moving the same direction.

This is easily controllable by the opponent, and there are certain crosshair placements where the movement can be mirrored.
Random movement if enemy is on target, else move away from crosshair: This is better, but it’s still exploitable. When the opponent triggers the random movement they can easily reposition or counter to take advantage since they know the bot will be moving in place.

A more complex script could yield more difficult targets, but it’s difficult to judge whether that is considered human. Also, larger scripts are definitely harder to exploit, but not impossible. The process to create such scripts would be particularly tedious, and is an endeavor I will leave to others. In the future, experimenting with random script generation based on a set of rules could potentially lead to some interesting results.
Self-Play Troubles
The next step was to let the bot learn through self-play. Pit two agents against each other and let them iteratively improve through repeated matches.
The following is my current best attempt for self-play. The agents trained for about 2 billion steps.
The problem is that self-play collapses in multiple ways. Reward shaping becomes critical but easily exploited, bots optimize single rewards to absurd extremes. An example is they learn to spin wildly to maximize crosshair angles, or mirror each other to maximize time-on-target. Like scripting heuristics, this is an endless process. Worse, agents converge to nearly identical playstyles. Humans have wildly different patterns and strategies, self-play produces clones. Some failures are now measurable (wall/corner bias, low-movement behavior), while others are currently qualitative (spin and mirror collapse).
Spin Collapse (POV + 2D Visualizer):
Mirror collapse (POV):
An attempted strategy was training via a curriculum. First, training against bots with scripted movement, gradually introducing learned opponents. This adds more complexity and just becomes more knobs to turn. Training runs are tracked with metrics like accuracy, win rate, entropy, standing behavior, and wall/corner percentages, plus periodic arena evaluations with position heatmaps. These checks catch issues like wall/corner camping and low-movement behavior reasonably well. Spin and mirror are specific examples of unexpected collapse that were not clearly captured in those measurements and were found through replay/video review.
Potential solutions could be vigorous hyperparameter and reward sweeps, and maybe introducing a “League” as in AlphaStar.
Current Focus and Next Steps
Where I am now: Metrics for measuring human data are an important missing piece. I do not have much measurability for “humanness” aside from just playing against the bots myself. Prior research in TrueSkill: A Bayesian Skill Rating System and Learning to Move Like Professional Counter-Strike Players shows metrics that could be valuable.
Collecting human data is an important piece to help measure for humanness. Human player data, even just against a bot, would be a good next step. Imitation learning with this would lead to baseline policies differing greatly from the self-play setup. However, it would have to be tested to see how they perform against a real human player.
Multiplayer and data collection would be the following steps towards human bots. Right now I am trapped in localhost, working on setting up a “King of the Hill” mode, where a pool of players will compete in a ladder of 1v1s, where winning moves up an arena, and losing moves down. Rather than a queue matchmaking system, this will help me collect data of many players interacting with varying skill levels. Human vs. human data will be very beneficial in creating bots that adapt to human play.
If you are interested in this project, let me know!
You can email me at agoldb35@binghamton.edu